
I am currently pursuing a PhD in Computer Science & Engineering at Indian Institute of Technology Jodhpur. My research focuses on Natural Language Processing and Computer Vision.
I design methods for contextual text error correction in Indic languages, multi-modal knowledge extraction, and low-resource learning.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Indian Institute of Technology JodhpurComputer Science & Engineering
Indian Institute of Technology JodhpurComputer Science & Engineering
Ph.D. Student2020 - 2026 (expected) -
 University of HyderabadM.Tech. in Information Technology2017 - 2019
University of HyderabadM.Tech. in Information Technology2017 - 2019 -
 Government Engineering College AjmerB.Tech. in Information Technology2012 - 2016
Government Engineering College AjmerB.Tech. in Information Technology2012 - 2016
News
Selected Publications (view all )

Post-ASR Correction for Low-Resource Rajasthani Language
Abhishek Bhandari and Gaurav Harit
ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP)
We introduce a multi-view, character-level Seq2Seq framework for post-ASR correction in the low-resource Rajasthani language. By using a gated mechanism to dynamically fuse outputs from Whisper and MMS models, our approach significantly reduces Character Error Rate (CER) and Word Error Rate (WER) on a newly created IndicTTS Rajasthani benchmark, outperforming single-view baselines and powerful LLMs like GPT-4o.
Post-ASR Correction for Low-Resource Rajasthani Language
Abhishek Bhandari and Gaurav Harit
ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP)
We introduce a multi-view, character-level Seq2Seq framework for post-ASR correction in the low-resource Rajasthani language. By using a gated mechanism to dynamically fuse outputs from Whisper and MMS models, our approach significantly reduces Character Error Rate (CER) and Word Error Rate (WER) on a newly created IndicTTS Rajasthani benchmark, outperforming single-view baselines and powerful LLMs like GPT-4o.
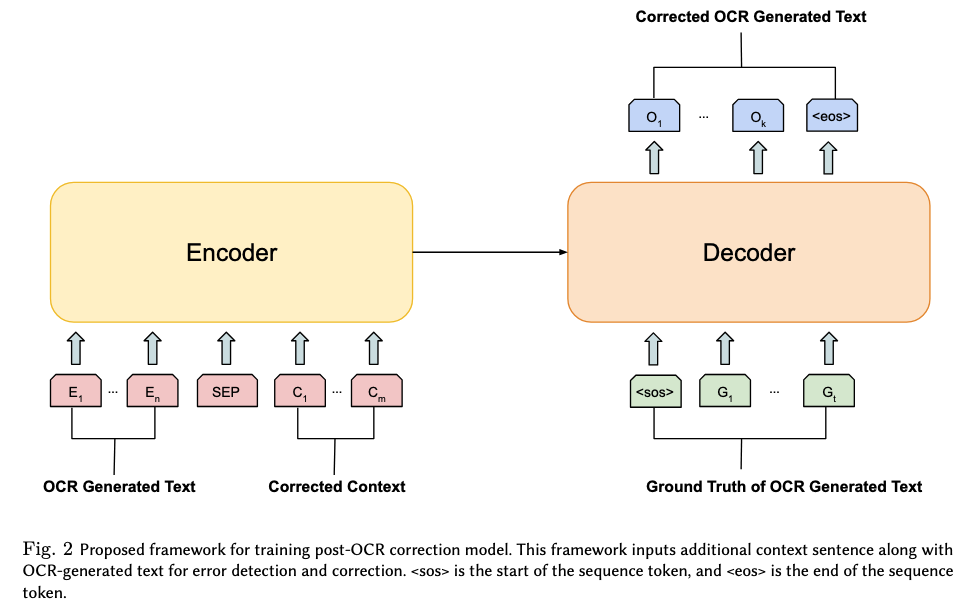
A Framework and Dataset for Contextual Post-OCR Correction
Abhishek Bhandari and Gaurav Harit
Accepted in ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP)
This paper presents a framework and dataset for contextual post-OCR correction to improve text quality in low-resource and noisy OCR settings.
A Framework and Dataset for Contextual Post-OCR Correction
Abhishek Bhandari and Gaurav Harit
Accepted in ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP)
This paper presents a framework and dataset for contextual post-OCR correction to improve text quality in low-resource and noisy OCR settings.
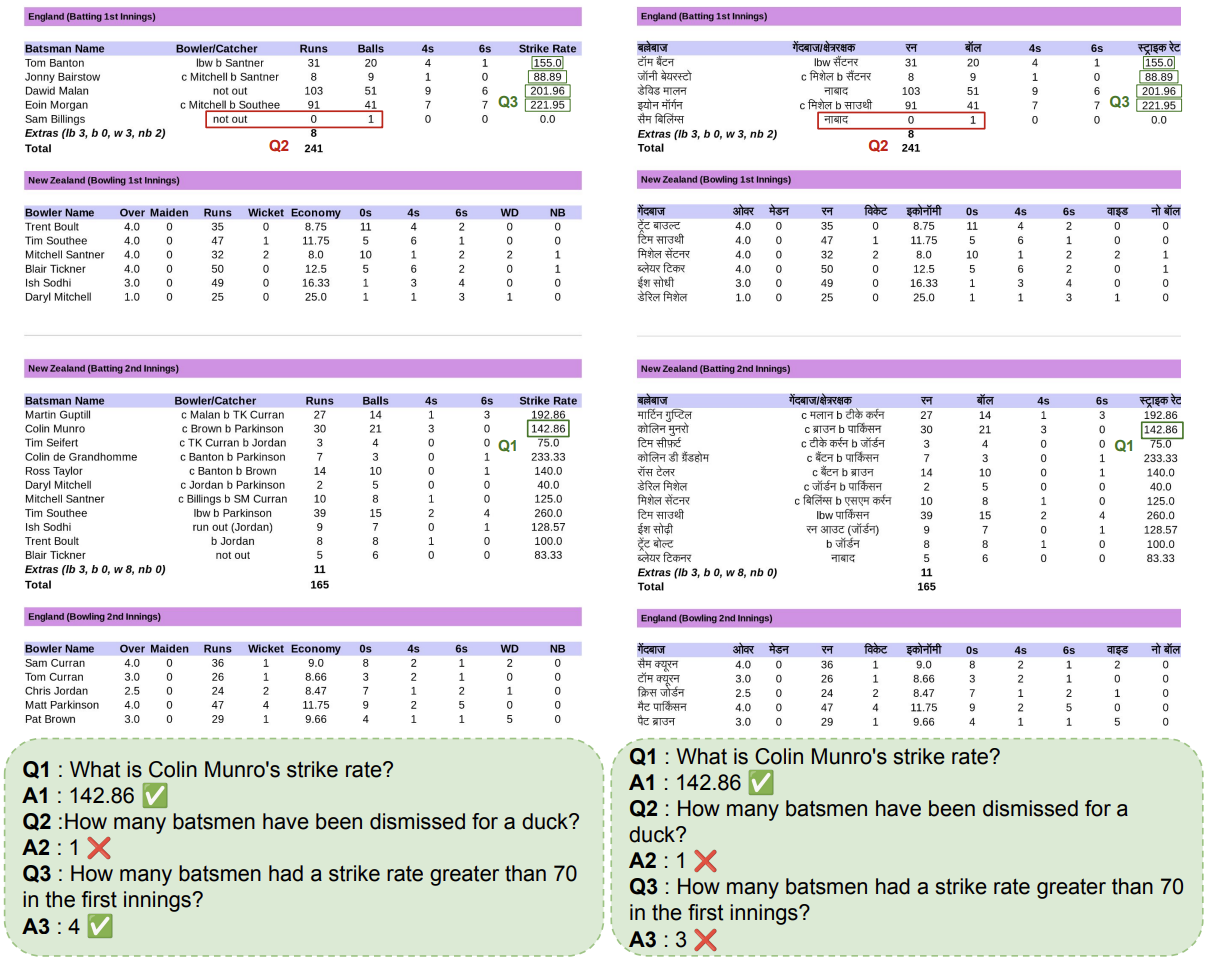
Mind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs
Somraj Gautam, AS Penamakuri, Abhishek Bhandari, Gaurav Harit
Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025)
This paper introduces MMCRICBENCH-3K, a benchmark for Visual Question Answering on cricket scorecards designed to evaluate large vision-language models on complex numerical and cross-lingual reasoning over semi-structured tabular images. Empirical results show that state-of-the-art models struggle with structure-aware numerical reasoning and cross-lingual generalization.
Mind the (Language) Gap: Towards Probing Numerical and Cross-Lingual Limits of LVLMs
Somraj Gautam, AS Penamakuri, Abhishek Bhandari, Gaurav Harit
Proceedings of the 5th Workshop on Multilingual Representation Learning (MRL 2025)
This paper introduces MMCRICBENCH-3K, a benchmark for Visual Question Answering on cricket scorecards designed to evaluate large vision-language models on complex numerical and cross-lingual reasoning over semi-structured tabular images. Empirical results show that state-of-the-art models struggle with structure-aware numerical reasoning and cross-lingual generalization.
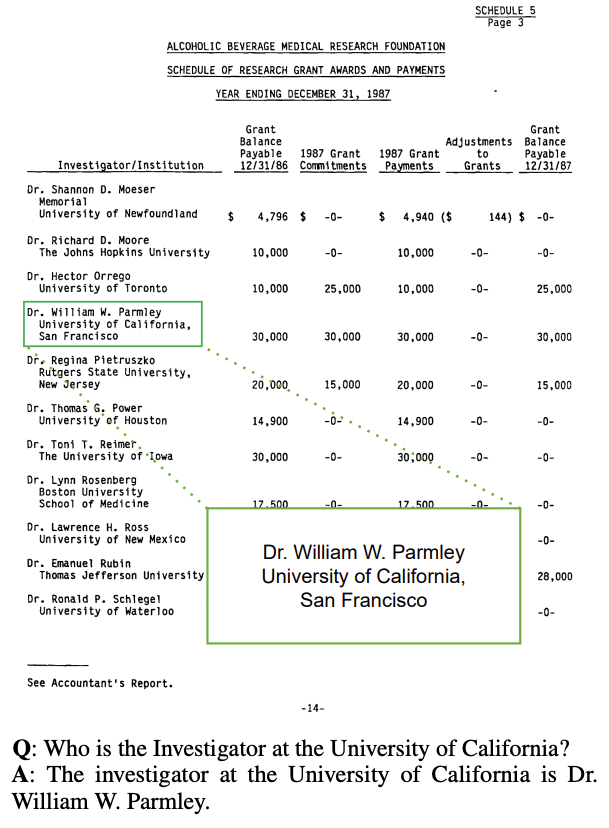
TabComp: A Dataset for Visual Table Reading Comprehension
Somraj Gautam, Abhishek Bhandari, Gaurav Harit
Findings of the Association for Computational Linguistics: NAACL 2025
This paper introduces TabComp, a dataset for visual table reading comprehension. The dataset is designed to advance research in understanding and extracting information from tables in documents.
TabComp: A Dataset for Visual Table Reading Comprehension
Somraj Gautam, Abhishek Bhandari, Gaurav Harit
Findings of the Association for Computational Linguistics: NAACL 2025
This paper introduces TabComp, a dataset for visual table reading comprehension. The dataset is designed to advance research in understanding and extracting information from tables in documents.
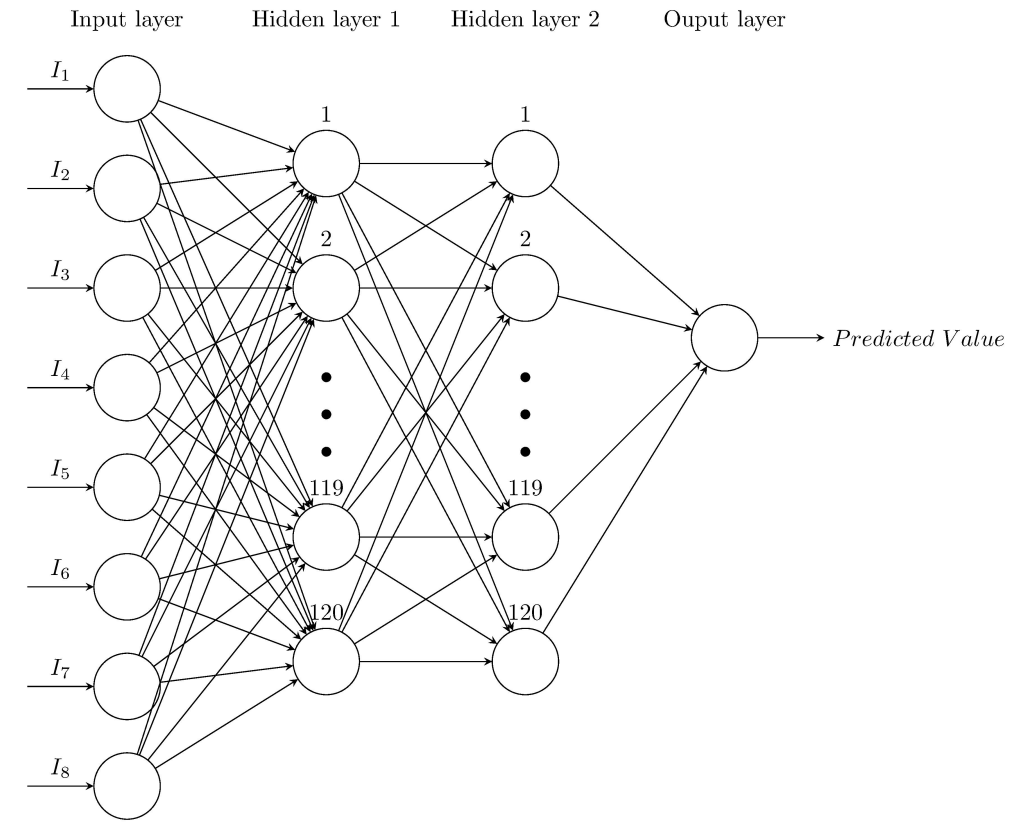
Reversible data hiding using multi-layer perceptron based pixel prediction
A Bhandari, S Sharma, R Uyyala, R Pal, M Verma
Proceedings of the 11th International Conference on Advances in Information Technology 2020
This paper presents a novel approach for reversible data hiding using multi-layer perceptron for pixel prediction. Reversible data hiding is a technique that allows the original cover media to be perfectly restored after the hidden data has been extracted.
Reversible data hiding using multi-layer perceptron based pixel prediction
A Bhandari, S Sharma, R Uyyala, R Pal, M Verma
Proceedings of the 11th International Conference on Advances in Information Technology 2020
This paper presents a novel approach for reversible data hiding using multi-layer perceptron for pixel prediction. Reversible data hiding is a technique that allows the original cover media to be perfectly restored after the hidden data has been extracted.